

The Language Big Data research team at Ocean University of China (OUC) published an article entitled “Construction and Validity of English-Chinese Translation Equivalents Dataset Based on Word Embedding Models” in Foreign Language Teaching and Research, a leading Chinese journal in foreign language studies, in its first 2026 issue (Vol. 58, No.1). The authors are Chen Shifa, Liu Yufeng, Zheng Binghan, and Li Xiaochen from OUC, and Yang Yi from Southwest Jiaotong University.
Translation equivalents refer to words in two languages that are semantically equivalent. However, cross-linguistic meanings rarely overlap completely, and a single English word may correspond to multiple Chinese translations with different degrees of equivalence. Traditional methods based on bilingual dictionaries or “first translations” are easily affected by subjective and inconsistent factors. To address this, the study proposes an approach based on word embedding models that uses semantic alignment as its core measure, and on this basis constructs an English-Chinese translation equivalents database and systematically verifies its validity.
To build the dataset, the team first integrated multiple sources to construct an English-Chinese translation mapping set. They compiled 1,652 English words from two translation equivalent databases. The researchers then collected translations from three authoritative English-Chinese dictionaries, two cross-lingual databases, and the Translation Process Research Database (CRITT TPR-DB). This resulted in a total of 10,978 translation pairs. Then, the team trained word embedding models using English and Chinese Wikipedia corpora as semantic spaces, extracted word vectors for these English words and their Chinese translations, and calculated semantic alignment through cosine similarity and Pearson correlation. In this way, they achieved a continuous and fine-grained measurement of the degree of semantic equivalence between English-Chinese translation pairs and constructed an English-Chinese translation equivalents dataset.
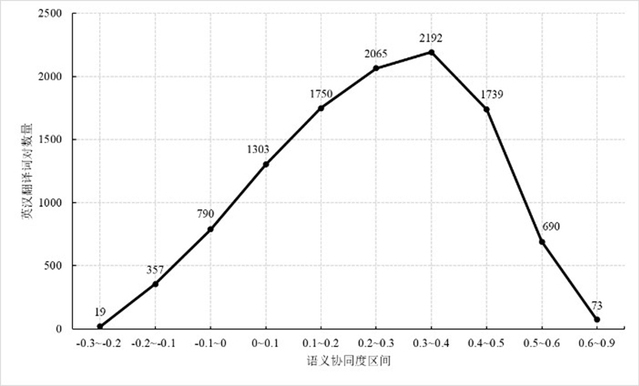
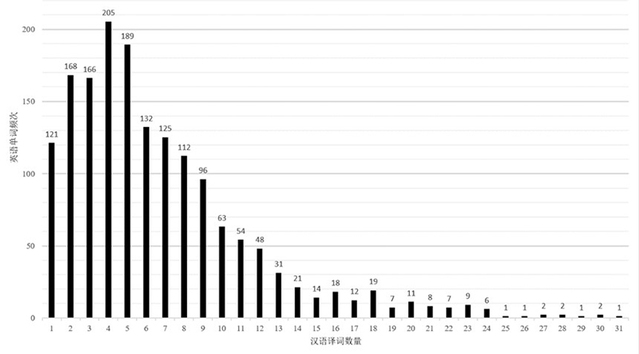
The dataset shows several notable features. It is large in scale, covering 1,652 English words and 10,978 Chinese translations, providing a more sufficient one-to-many mapping between the two languages. In structural terms, semantic alignment values exhibit a continuous distribution, with evident non-equivalence among many translation pairs. Most pairs fall within the low-to-mid range, and a certain proportion show negative alignment values, suggesting that some translation equivalents may display contrasting usage patterns across languages. In addition, the translations of source words exhibit strong ambiguity, with 92.7% of English words corresponding to two or more Chinese translations, reflecting the complexity of English-Chinese lexical mapping and the common coexistence of multiple translation options.
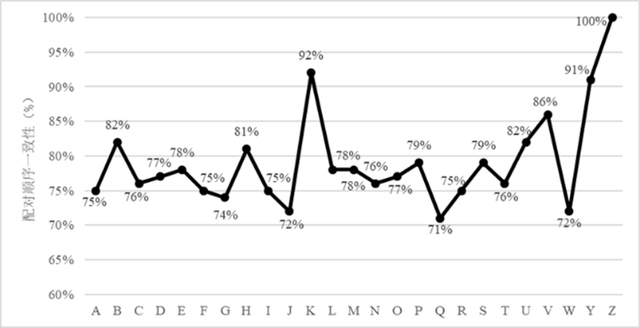
In terms of validity, the study adopted a twofold validation strategy combining comparison with existing resources and replication across different semantic spaces. First, the researchers examined correlations between semantic alignment values and human semantic similarity ratings, as well as the usage probabilities of major translation equivalents in existing databases. In both cases, the correlations were significantly positive, indicating that semantic alignment reflects bilinguals’ perceived semantic similarity between translation pairs. Second, the team reconstructed the dataset using alternative semantic spaces. The results showed that semantic alignment values remained highly consistent across semantic spaces and that the ranking of Chinese translations for the same English word was also highly stable, demonstrating the robustness and reproducibility of the method.
Overall, the study concludes that the English-Chinese translation equivalents dataset based on word embedding models is highly objective and faithfully reflects the degree of semantic equivalence between English-Chinese translation pairs, thereby providing a large-scale, continuously measurable resource for future research on bilingual processing, translation processing, and related experiments.




